Spring Cloud Sleuth 与 Zipkin 集成
什么是 Zipkin?
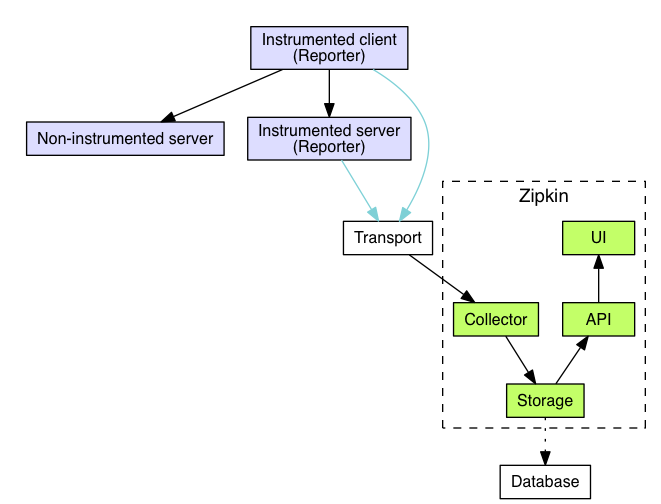
Zipkin 是一个开源的分布式追踪系统,由 Twitter 公司开发,用于收集微服务架构中的时序数据,以解决在微服务架构中的延迟问题。它管理这些数据的收集和查找,并提供了一个可视化界面,帮助开发者直观地了解请求在各个服务之间的流转情况。
Zipkin 的主要功能包括:
- 数据收集:收集来自各个服务的追踪数据
- 数据存储:将追踪数据存储在内存、MySQL、Elasticsearch 等存储系统中
- 数据查询:提供 API 查询追踪数据
- 数据可视化:通过 Web UI 展示追踪数据,包括服务依赖图、调用链路图等
Zipkin 架构
Zipkin 由以下几个核心组件组成:
- Collector:收集器,用于收集和验证追踪数据
- Storage:存储,用于存储和索引追踪数据
- API:提供 REST API,用于查询追踪数据
- UI:Web 界面,用于可视化展示追踪数据
环境准备
1. 启动 Zipkin 服务器
有多种方式可以启动 Zipkin 服务器,最简单的是使用 Docker:
docker run -d -p 9411:9411 openzipkin/zipkin或者使用 Java 命令:
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar启动后,可以通过访问 http://localhost:9411 来打开 Zipkin 的 Web 界面。
2. 添加依赖
在您的 Spring Boot 项目的 pom.xml 中添加 Sleuth 和 Zipkin 相关依赖:
<dependencies>
<!-- Spring Boot Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring Cloud Sleuth -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<!-- Spring Cloud Zipkin -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
</dependencies>3. 配置应用
在 application.yml 中添加 Zipkin 相关配置:
spring:
application:
name: service-a # 应用名称,会显示在追踪日志和 Zipkin 中
sleuth:
sampler:
probability: 1.0 # 采样率,1.0 表示 100% 采样
zipkin:
base-url: http://localhost:9411 # Zipkin 服务器地址
sender:
type: web # 使用 HTTP 方式发送数据到 Zipkin
logging:
pattern:
level: "%5p [${spring.application.name:},%X{traceId:-},%X{spanId:-},%X{exportable:-}]"基本使用
配置完成后,您的应用会自动将追踪数据发送到 Zipkin 服务器。下面我们创建一个简单的示例来演示 Sleuth 与 Zipkin 的集成。
1. 创建服务 A
package com.example.servicea;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;
@SpringBootApplication
public class ServiceAApplication {
public static void main(String[] args) {
SpringApplication.run(ServiceAApplication.class, args);
}
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}package com.example.servicea.controller;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
@RestController
public class ServiceAController {
private static final Logger log = LoggerFactory.getLogger(ServiceAController.class);
@Autowired
private RestTemplate restTemplate;
@GetMapping("/start")
public String start() {
log.info("Service A received request");
String response = restTemplate.getForObject("http://localhost:8082/process", String.class);
log.info("Service A received response from Service B: {}", response);
return "Service A => " + response;
}
}2. 创建服务 B
package com.example.serviceb;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class ServiceBApplication {
public static void main(String[] args) {
SpringApplication.run(ServiceBApplication.class, args);
}
}package com.example.serviceb.controller;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ServiceBController {
private static final Logger log = LoggerFactory.getLogger(ServiceBController.class);
@GetMapping("/process")
public String process() {
log.info("Service B processing request");
// 模拟处理时间
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "Processed by Service B";
}
}3. 配置服务 A 和服务 B
服务 A 的 application.yml:
server:
port: 8081
spring:
application:
name: service-a
sleuth:
sampler:
probability: 1.0
zipkin:
base-url: http://localhost:9411
sender:
type: web服务 B 的 application.yml:
server:
port: 8082
spring:
application:
name: service-b
sleuth:
sampler:
probability: 1.0
zipkin:
base-url: http://localhost:9411
sender:
type: web4. 测试集成
- 启动 Zipkin 服务器
- 启动服务 A 和服务 B
- 访问
http://localhost:8081/start多次,触发服务间调用 - 访问
http://localhost:9411查看 Zipkin 界面
在 Zipkin 界面中,您可以:
- 查看服务依赖图(Dependencies)
- 搜索特定的追踪(Search)
- 查看详细的调用链路(Trace)
高级配置
1. 使用消息队列发送追踪数据
在高流量系统中,使用 HTTP 直接发送追踪数据到 Zipkin 可能会影响性能。此时可以考虑使用消息队列(如 RabbitMQ 或 Kafka)来异步发送追踪数据。
以 RabbitMQ 为例,首先添加依赖:
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>然后修改配置:
spring:
zipkin:
sender:
type: rabbit # 使用 RabbitMQ 发送数据
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest2. 自定义采样策略
Sleuth 默认使用概率采样策略,您也可以实现自定义的采样策略:
package com.example.config;
import org.springframework.cloud.sleuth.sampler.SamplerFunction;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class SleuthConfig {
@Bean
public SamplerFunction<String> myHttpSampler() {
return new SamplerFunction<String>() {
@Override
public Boolean trySample(String request) {
// 对于 /health 和 /info 端点不采样
if (request.contains("/health") || request.contains("/info")) {
return false;
}
// 对于其他请求 100% 采样
return true;
}
};
}
}3. 添加自定义标签
您可以为 Span 添加自定义标签,以便在 Zipkin 中查看更多信息:
@RestController
public class ServiceAController {
private static final Logger log = LoggerFactory.getLogger(ServiceAController.class);
@Autowired
private RestTemplate restTemplate;
@Autowired
private Tracer tracer;
@GetMapping("/start")
public String start(@RequestParam(value = "name", defaultValue = "World") String name) {
log.info("Service A received request with name: {}", name);
// 获取当前 Span 并添加标签
Span currentSpan = tracer.currentSpan();
if (currentSpan != null) {
currentSpan.tag("user.name", name);
}
String response = restTemplate.getForObject("http://localhost:8082/process?name=" + name, String.class);
log.info("Service A received response from Service B: {}", response);
return "Service A => " + response;
}
}存储选项
Zipkin 支持多种存储后端,默认使用内存存储,但在生产环境中,建议使用持久化存储。
1. MySQL 存储
# 启动 Zipkin 服务器,使用 MySQL 存储
java -jar zipkin.jar --STORAGE_TYPE=mysql --MYSQL_HOST=localhost --MYSQL_TCP_PORT=3306 --MYSQL_DB=zipkin --MYSQL_USER=zipkin --MYSQL_PASS=zipkin2. Elasticsearch 存储
# 启动 Zipkin 服务器,使用 Elasticsearch 存储
java -jar zipkin.jar --STORAGE_TYPE=elasticsearch --ES_HOSTS=http://localhost:9200最佳实践
性能考虑
- 采样率控制:在高流量系统中,适当降低采样率
- 异步发送:使用消息队列异步发送追踪数据
- 存储选择:根据数据量选择合适的存储后端
- 数据保留:设置合理的数据保留期限,避免存储空间过度增长
实施建议
- 服务命名:使用有意义的服务名称,便于在 Zipkin 中识别
- 添加标签:为关键操作添加自定义标签,提供更多上下文信息
- 监控 Zipkin:监控 Zipkin 服务器的健康状况和性能
- 集成告警:基于追踪数据设置告警规则,及时发现异常
常见问题
1. 追踪数据没有显示在 Zipkin 中?
可能的原因和解决方法:
- Zipkin 服务器未启动:确保 Zipkin 服务器正常运行
- 配置错误:检查
spring.zipkin.base-url配置是否正确 - 网络问题:确保应用可以访问 Zipkin 服务器
- 采样率设置:检查
spring.sleuth.sampler.probability是否大于 0
如果使用消息队列,还需要检查消息队列的连接是否正常。
2. 如何在生产环境中部署 Zipkin?
在生产环境中部署 Zipkin 时,建议:
- 使用容器化部署:使用 Docker 或 Kubernetes 部署 Zipkin
- 配置持久化存储:使用 MySQL 或 Elasticsearch 存储追踪数据
- 设置资源限制:根据数据量设置合理的内存和 CPU 限制
- 配置高可用:考虑部署多个 Zipkin 实例,使用负载均衡
- 设置安全访问:配置认证和授权,保护 Zipkin 界面和 API
# Docker Compose 示例
version: '3'
services:
zipkin:
image: openzipkin/zipkin
ports:
- "9411:9411"
environment:
- STORAGE_TYPE=elasticsearch
- ES_HOSTS=http://elasticsearch:9200
depends_on:
- elasticsearch
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.10.0
ports:
- "9200:9200"
environment:
- discovery.type=single-node
- xpack.security.enabled=false总结
本教程详细介绍了 Spring Cloud Sleuth 与 Zipkin 的集成,包括:
- ✅ Zipkin 基础:Zipkin 的概念和架构
- ✅ 环境配置:启动 Zipkin 服务器和配置应用
- ✅ 基本使用:创建示例应用并测试集成
- ✅ 高级配置:使用消息队列、自定义采样策略和添加标签
- ✅ 存储选项:MySQL 和 Elasticsearch 存储
- ✅ 最佳实践:性能考虑和实施建议
下一步学习
- 学习 Spring Cloud Sleuth 高级特性
- 了解其他分布式追踪系统,如 Jaeger、SkyWalking 等
希望这个教程对您有所帮助!如果您有任何问题,欢迎在评论区讨论。